Les autres réponses n'utilisent pas la définition de la théorie de l'information de l'entropie. La définition mathématique est définie comme une fonction basée uniquement sur une distribution de probabilité. Il est défini pour la fonction de densité de probabilité p comme la somme de p (x) * -log (p (x)) de chaque résultat possible x .
Les unités d'entropie sont logarithmiques. En général, deux sont utilisés pour la base du logarithme, nous disons donc qu'un système stochastique a n bits d'entropie . (D'autres bases peuvent être utilisées. Pour la base e , vous mesureriez plutôt l'entropie "nats", pour le logarithme nat ural, mais la base deux et les "bits" sont plus courants.)
Le terme vient de la théorie de l'information. L'entropie est, bien entendu, liée à l'information. (Une autre raison pour laquelle nous disons "bits".) Mais vous pouvez aussi décrire l'entropie comme une mesure de "l'imprévisibilité".
Lancer une pièce juste une fois (dans le monde idéal) produit 1 bit d'entropie. Lancer une pièce deux fois produit deux bits. Etc. Les distributions uniformes (discrètes) sont les distributions les plus simples pour calculer l'entropie car chaque terme additionné est identique. Vous pouvez simplifier l'équation pour l'entropie d'une variable discrète uniforme X avec n résultats chacun avec 1 / n probabilité de
H (X) = n * 1 / n * -log (1 / n) = log (n)
Vous devriez pouvoir voir comment on peut obtenir l'entropie hors du système qui est un ou plusieurs tirages de pièces avec juste connaissance du nombre de tirages de pièces à enregistrer.
L'entropie des distributions non uniformes (discrètes) est également facile à calculer. Cela nécessite juste plus d'étapes. Je vais utiliser l'exemple de tirage au sort pour relier à nouveau l'entropie à l'imprévisibilité. Et si vous utilisiez à la place une pièce biaisée? Eh bien, l'entropie est
H = p (têtes) * -log (p (têtes)) + p (queues) * -log (p (queues))
Si vous indiquez que vous obtenez ceci
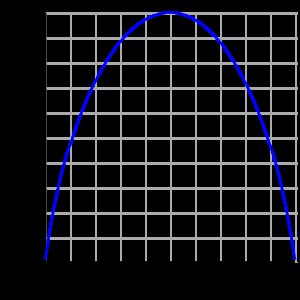
Vous voyez? Moins un tirage de pièces (distribution) est juste (uniforme), moins il a d'entropie. L'entropie est maximisée pour le type de tirage de pièce qui est le plus imprévisible: un tirage de pièce juste. Les lancers de pièces biaisés contiennent encore une certaine entropie tant que les têtes et les queues sont encore possibles. L'entropie (imprévisibilité) diminue lorsque la pièce devient plus biaisée. Tout ce qui est sûr à 100% n'a aucune entropie.
Il est important de savoir que c'est l'idée de lancer des pièces qui a une entropie, et non le résultat des lancers de pièces eux-mêmes. Vous ne pouvez pas déduire d'un échantillon x de la distribution X quelle est la probabilité p (x) de x . Tout ce que vous savez, c'est qu'il est non nul. Et avec seulement x , vous n'avez aucune idée du nombre d'autres résultats possibles ou de leurs probabilités individuelles. Par conséquent, vous ne pouvez pas calculer l'entropie en regardant simplement un échantillon.
Lorsque vous voyez une chaîne "HTHTHT" , vous ne savez pas si elle provient d'une séquence de six lancers de pièces justes (6 bits d'entropie), une séquence de retournement de pièces biaisée (< 6 bits), une chaîne générée aléatoirement à partir de la distribution uniforme des 6 lettres majuscules (6 * log_2 (26) ou environ 28 bits), ou s'il provient d'une séquence qui alterne simplement entre 'H' et 'T' (0 bits).
Pour la même raison, vous ne pouvez pas calculer l'entropie d'un seul mot de passe. Tout outil qui vous indique l'entropie d'un mot de passe que vous entrez est incorrect ou déforme ce qu'il entend par entropie. (Et peut-être récolter des mots de passe.) Seuls les systèmes avec une distribution de probabilité peuvent avoir une entropie. Vous ne pouvez pas calculer la véritable entropie de ce système avec la connaissance des probabilités exactes et il n'y a aucun moyen de contourner cela.
On peut cependant estimer l'entropie, mais cela nécessite encore quelques connaissances (ou hypothèses) de la distribution. Si vous supposez qu'un mot de passe de type k a été généré à partir de l'une des rares distributions uniformes avec un alphabet A , vous pouvez estimer l'entropie à log_2 (1 / | A |) . | A | étant la taille de l'alphabet. De nombreux estimateurs de la force des mots de passe utilisent cette méthode (naïve). S'ils voient que vous n'utilisez que des minuscules, ils supposent que | A | = 26 . S'ils voient un mélange de majuscules et de minuscules, ils supposent | A | = 52 . C'est pourquoi un prétendu calculateur de force de mot de passe peut vous dire que "Password1" est des milliers de fois plus sécurisé que "password" . Il émet des hypothèses sur la distribution statistique des mots de passe qui ne sont pas nécessairement justifiées.
Certains vérificateurs de force de mot de passe ne présentent pas ce comportement, mais cela ne signifie pas qu'il s'agit d'estimations exactes. Ils sont simplement programmés pour rechercher plus de modèles. Nous pouvons faire des estimations plus éclairées de la force du mot de passe en fonction des comportements humains observés ou imaginés des mots de passe, mais nous ne pouvons jamais calculer une valeur d'entropie qui n'est pas une estimation.
Et comme je l'ai dit plus tôt, il est faux de dire que les mots de passe eux-mêmes ont une entropie qui leur est associée. Quand les gens disent qu'un mot de passe a ___ entropie alors, s'ils savent de quoi ils parlent, ils l'utilisent vraiment en abrégé pour "ce mot de passe a été généré en utilisant un processus qui a ____ entropie."
Certaines personnes préconisent que les mots de passe soient générés par ordinateur plutôt que par l'homme. C'est parce que les humains sont mauvais pour trouver des mots de passe à haute entropie. Le biais humain produit des distributions de mots de passe non uniformes. Même les mots de passe longs que les gens choisissent sont plus prévisibles que prévu. Pour les mots de passe générés par ordinateur, nous pouvons connaître l'entropie exacte d'un espace de mot de passe parce qu'un programmeur a créé cet espace de mot de passe. Nous sommes en mesure de connaître l'entropie de mot de passe générée par la machine sans estimation, en supposant que nous utilisons un RNG sécurisé. Diceware est une autre méthode de génération de mots de passe que les gens préconisent et qui possède les mêmes propriétés. Il ne nécessite aucun ordinateur et suppose à la place que vous avez un dé à six faces.
Si un mot de passe est généré avec n bits d'entropie, nous pouvons estimer le nombre de suppositions a Le cracker de mot de passe doit être égal à 2 ^ (n-1). Cependant, il s'agit d'une estimation prudente. La force du mot de passe et l'entropie ne sont pas synonymes. L'estimation basée sur l'entropie suppose que le pirate connaît votre processus de génération de mot de passe individuel. La force du mot de passe basée sur l'entropie suit le principe de Kerckhoffs. Il mesure la force du mot de passe dans un sens (puisque l'entropie mesure l'imprévisibilité) en utilisant l'état d'esprit security-through-obscurity is not security . Si vous gardez consciemment l'entropie à l'esprit lors de la génération de mots de passe, vous pouvez choisir une méthode de génération de mot de passe avec une entropie élevée et obtenir une limite inférieure sur la sécurité de votre mot de passe.
Tant que le mot de passe est mémorable / utilisable il n'y a rien de mal à utiliser des calculs d'entropie vraie comme estimation prudente de la force du mot de passe; mieux vaut sous-estimer (et utiliser des mots de passe générés par ordinateur ou générés par des dés) que surestimer la force du mot de passe (comme le font les algorithmes d'estimation de la force des mots de passe avec les mots de passe générés par l'homme.)
La réponse à votre question est Non. Il n'existe pas de moyen fiable de vérifier l'entropie du mot de passe. C'est en fait mathématiquement impossible.
#/media/File:Binary_entropy_plot.svg)